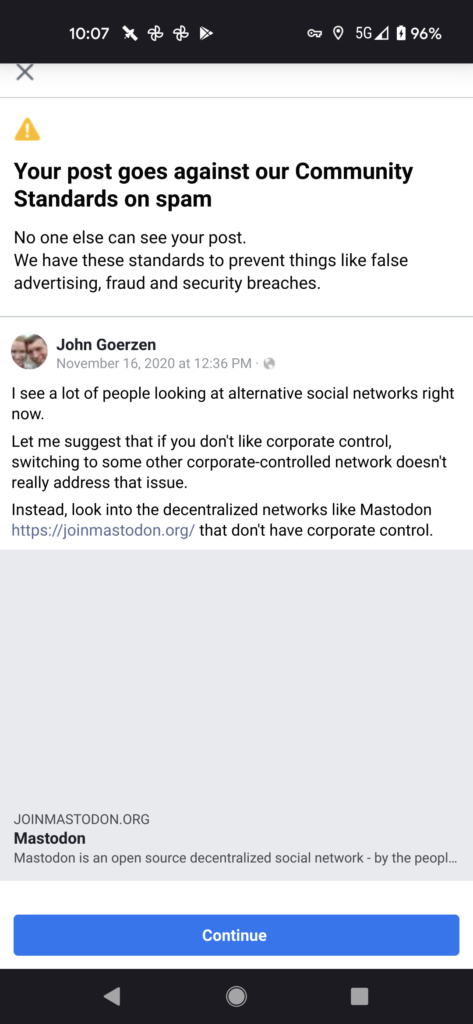
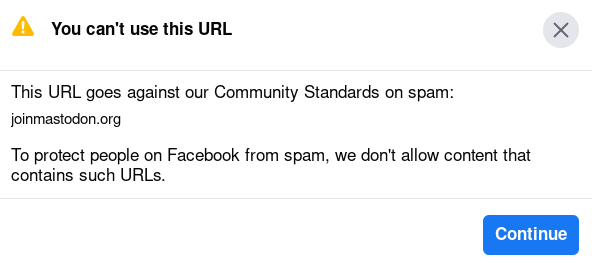
It seems that lately I’ve written several shell implementations of a simple queue that enforces ordered execution of jobs that may arrive out of order. After writing this for the nth time in bash, I decided it was time to do it properly. But first, a word on the why of it all.
Why did I bother?
My needs arose primarily from handling Backups over Asynchronous Communication methods – in this case, NNCP. When backups contain incrementals that are unpacked on the destination, they must be applied in the correct order.
In some cases, like ZFS, the receiving side will detect an out-of-order backup file and exit with an error. In those cases, processing in random order is acceptable but can be slow if, say, hundreds or thousands of hourly backups have stacked up over a period of time. The same goes for using gitsync-nncp to synchronize git repositories. In both cases, a best effort based on creation date is sufficient to produce a significant performance improvement.
With other cases, such as tar or dar backups, the receiving cannot detect out of order incrementals. In those situations, the incrementals absolutely must be applied with strict ordering. There are many other situations that arise with these needs also. Filespooler is the answer to these.
Existing Work
Before writing my own program, I of course looked at what was out there already. I looked at celeary, gearman, nq, rq, cctools work queue, ts/tsp (task spooler), filequeue, dramatiq, GNU parallel, and so forth.
Unfortunately, none of these met my needs at all. They all tended to have properties like:
- An extremely complicated client/server system that was incompatible with piping data over existing asynchronous tools
- A large bias to processing of small web requests, resulting in terrible inefficiency or outright incompatibility with jobs in the TB range
- An inability to enforce strict ordering of jobs, especially if they arrive in a different order from how they were queued
Many also lacked some nice-to-haves that I implemented for Filespooler:
- Support for the encryption and cryptographic authentication of jobs, including metadata
- First-class support for arbitrary compressors
- Ability to use both stream transports (pipes) and filesystem-like transports (eg, rclone mount, S3, Syncthing, or Dropbox)
Introducing Filespooler
Filespooler is a tool in the Unix tradition: that is, do one thing well, and integrate nicely with other tools using the fundamental Unix building blocks of files and pipes. Filespooler itself doesn’t provide transport for jobs, but instead is designed to cooperate extremely easily with transports that can be written to as a filesystem or piped to – which is to say, almost anything of interest.
Filespooler is written in Rust and has an extensive Filespooler Reference as well as many tutorials on its homepage. To give you a few examples, here are some links:
- Using Filespooler over Syncthing (and the most comprehensive tutorial)
- Using Filespooler over NNCP
- Compressing Filespooler Jobs
- Encrypting Filespooler Jobs with GPG or Age
- Guidelines for Writing To Filespooler Queues Without Using Filespooler
Basics of How it Works
Filespooler is intentionally simple:
- The sender maintains a sequence file that includes a number for the next job packet to be created.
- The receiver also maintains a sequence file that includes a number for the next job to be processed.
fspl preparecreates a Filespooler job packet and emits it to stdout. It includes a small header (<100 bytes in most cases) that includes the sequence number, creation timestamp, and some other useful metadata.- You get to transport this job packet to the receiver in any of many simple ways, which may or may not involve Filespooler’s assistance.
- On the receiver, Filespooler (when running in the default strict ordering mode) will simply look at the sequence file and process jobs in incremental order until it runs out of jobs to process.
The name of job files on-disk matches a pattern for identification, but the content of them is not significant; only the header matters.
You can send job data in three ways:
- By piping it to
fspl prepare - By setting certain environment variables when calling
fspl prepare - By passing additional command-line arguments to
fspl prepare, which can optionally be passed to the processing command at the receiver.
Data piped in is added to the job “payload”, while environment variables and command-line parameters are encoded in the header.
Basic usage
Here I will excerpt part of the Using Filespooler over Syncthing tutorial; consult it for further detail. As a bit of background, Syncthing is a FLOSS decentralized directory synchronization tool akin to Dropbox (but with a much richer feature set in many ways).
Preparation
First, on the receiver, you create the queue (passing the directory name to -q):
sender$ fspl queue-init -q ~/sync/b64queue
Now, we can send a job like this:
sender$ echo Hi | fspl prepare -s ~/b64seq -i - | fspl queue-write -q ~/sync/b64queue
Let’s break that down:
- First, we pipe “Hi” to
fspl prepare. fspl preparetakes two parameters:-s seqfilegives the path to a sequence file used on the sender side. This file has a simple number in it that increments a unique counter for every generated job file. It is matched with thenextseqfile within the queue to make sure that the receiver processes jobs in the correct order. It MUST be separate from the file that is in the queue and should NOT be placed within the queue. There is no need to sync this file, and it would be ideal to not sync it.- The
-ioption tellsfspl prepareto read a file for the packet payload.-i -tells it to read stdin for this purpose. So, the payload will consist of three bytes: “Hi\n” (that is, including the terminating newline thatechowrote)
- Now,
fspl preparewrites the packet to its stdout. We pipe that intofspl queue-write:fspl queue-writereads stdin and writes it to a file in the queue directory in a safe manner. The file will ultimately match thefspl-*.fsplpattern and have a random string in the middle.
At this point, wait a few seconds (or however long it takes) for the queue files to be synced over to the recipient.
On the receiver, we can see if any jobs have arrived yet:
receiver$ fspl queue-ls -q ~/sync/b64queue
ID creation timestamp filename
1 2022-05-16T20:29:32-05:00 fspl-7b85df4e-4df9-448d-9437-5a24b92904a4.fspl
Let’s say we’d like some information about the job. Try this:
receiver$ $ fspl queue-info -q ~/sync/b64queue -j 1
FSPL_SEQ=1
FSPL_CTIME_SECS=1652940172
FSPL_CTIME_NANOS=94106744
FSPL_CTIME_RFC3339_UTC=2022-05-17T01:29:32Z
FSPL_CTIME_RFC3339_LOCAL=2022-05-16T20:29:32-05:00
FSPL_JOB_FILENAME=fspl-7b85df4e-4df9-448d-9437-5a24b92904a4.fspl
FSPL_JOB_QUEUEDIR=/home/jgoerzen/sync/b64queue
FSPL_JOB_FULLPATH=/home/jgoerzen/sync/b64queue/jobs/fspl-7b85df4e-4df9-448d-9437-5a24b92904a4.fspl
This information is intentionally emitted in a format convenient for parsing.
Now let’s run the job!
receiver$ fspl queue-process -q ~/sync/b64queue --allow-job-params base64
SGkK
There are two new parameters here:
--allow-job-paramssays that the sender is trusted to supply additional parameters for the command we will be running.base64is the name of the command that we will run for every job. It will:- Have environment variables set as we just saw in
queue-info - Have the text we previously prepared – “Hi\n” – piped to it
- Have environment variables set as we just saw in
By default, fspl queue-process doesn’t do anything special with the output; see Handling Filespooler Command Output for details on other options. So, the base64-encoded version of our string is “SGkK”. We successfully sent a packet using Syncthing as a transport mechanism!
At this point, if you do a fspl queue-ls again, you’ll see the queue is empty. By default, fspl queue-process deletes jobs that have been successfully processed.
For more
See the Filespooler homepage.
This blog post is also available as a permanent, periodically-updated page.