… and the case against bzip2
Compression is with us all the time. I want to talk about general-purpose lossless compression here.
There is a lot of agonizing over compression ratios: the size of output for various sizes of input. For some situations, this is of course the single most important factor. For instance, if you’re Linus Torvalds putting your code out there for millions of people to download, the benefit of saving even a few percent of file size is well worth the cost of perhaps 50% worse compression performance. He compresses a source tarball once a month maybe, and we are all downloading it thousands of times a day.
On the other hand, when you’re doing backups, the calculation is different. Your storage media costs money, but so does your CPU. If you have a large photo collection or edit digital video, you may create 50GB of new data in a day. If you use a compression algorithm that’s too slow, your backup for one day may not complete before your backup for the next day starts. This is even more significant a problem when you consider enterprises backing up terabytes of data each day.
So I want to think of compression both in terms of resulting size and performance. Onward…
Starting Point
I started by looking at the practical compression test, which has some very useful charts. He has charted savings vs. runtime for a number of different compressors, and with the range of different settings for each.
If you look at his first chart, you’ll notice several interesting things:
- gzip performance flattens at about -5 or -6, right where the manpage tells us it will, and in line with its defaults.
- 7za -2 (the LZMA algorithm used in 7-Zip and p7zip) is both faster and smaller than any possible bzip2 combination. 7za -3 gets much slower.
- bzip2’s performance is more tightly clustered than the others, both in terms of speed and space. bzip2 -3 is about the same speed as -1, but gains some space.
All this was very interesting, but had one limitation: it applied only to the gimp source tree, which is something of a best-case scenario for compression tools.
A 6GB Test
I wanted to try something a bit more interesting. I made an uncompressed tar file of /usr on my workstation, which comes to 6GB of data. My /usr contains highly compressible data such as header files and source code, ELF binaries and libraries, already-compressed documentation files, small icons, and the like. It is a large, real-world mix of data.
In fact, every compression comparison I saw was using data sets less than 1GB in size — hardly representative of backup workloads.
Let’s start with the numbers:
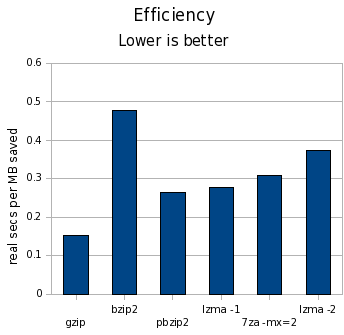
| Tool | MB saved | Space vs. gzip | Time vs. gzip | Cost | gzip | 3398 | 100.00% | 100.00% | 0.15 |
|---|---|---|---|---|
| bzip2 | 3590 | 92.91% | 333.05% | 0.48 |
| pbzip2 | 3587 | 92.99% | 183.77% | 0.26 |
| lzma -1 | 3641 | 91.01% | 195.58% | 0.28 |
| lzma -2 | 3783 | 85.76% | 273.83% | 0.37 |
In the “MB saved” column, higher numbers are better; in all other columns, lower numbers are better. I’m using clock seconds here on a dual-core machine. The cost column is clock seconds per MB saved.
What does this tell us?
- bzip2 can do roughly 7% better than gzip, at a cost of a compression time more than 3 times as long.
- lzma -1 compresses better than bzip2 -9 in less than twice the time of gzip. That is, it is significantly faster and marginally smaller than bzip2.
- lzma -2 is significantly smaller and still somewhat faster than bzip2.
- pbzip2 achieves better wall clock performance, though not better CPU time performance, than bzip2 — though even then, it is only marginally better than lzma -1 on a dual-core machine.
Some Pretty Charts
First, let’s see how the time vs. size numbers look:
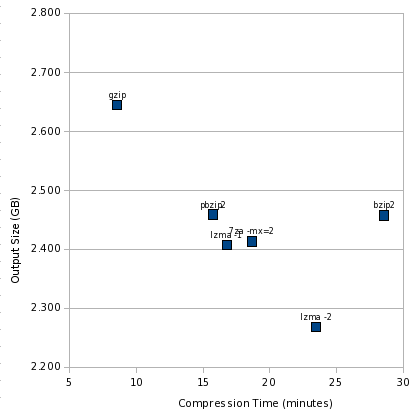
Like the other charts, the best area is the lower left, and worst is upper right. It’s clear we have two outliers: gzip and bzip2. And a cluster of pretty similar performers.
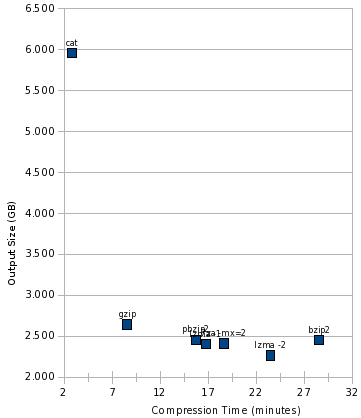
This view somewhat magnifies the differences, though. Let’s add cat to the mix:
And finally, look at the cost:
Conclusions
First off, the difference in time is far larger than the difference in space. We’re talking a difference of 15% at the most in terms of space, but orders of magnitude for time.
I think this pretty definitively is a death knell for bzip2. lzma -1 can achieve better compression in significantly less time, and lzma -2 can achieve significantly better compression in a little less time.
pbzip2 can help even that out in terms of clock time on multicore machines, but 7za already has a parallel LZMA implementation, and it seems only a matter of time before /usr/bin/lzma gets it too. Also, if I were to chart CPU time, the numbers would be even less kind to pbzip2 than to bzip2.
bzip2 does have some interesting properties, such as resetting everything every 900K, which could provide marginally better safety than any other compressor here — though I don’t know if lzma provides similar properties, or could.
I think a strong argument remains that gzip is most suitable for backups in the general case. lzma -1 makes a good contender when space is at more of a premium. bzip2 doesn’t seem to make a good contender at all now that we have lzma.
I have also made my spreadsheet (OpenOffice format) containing the raw numbers and charts available for those interested.
Update
Part 2 of this story is now available, which considers more compression tools, and looks at performance compressing files individually rather than the large tar file.
I took a disk image of a Vista partition before wiping it off my new Thinkpad’s hard drive (I don’t plan to ever use the Vista, but who knows, and it doesn’t come with a disk.) The compression time was about on par with what you describe, as bzip2 took much longer than gzip. What worried me was that bzip2 was corrupting the data. A bunzipped file was not identical to the file before it was bzipped. The bzip2 web page says this might be a memory error. I tried replicating this bug on my 2-year-old desktop with an old AMD Athlon 64, but the bzip2 of this 20GB file didn’t finish after an hour and I just gave up.
I have never had any issues with bzip2 corrupting data. I believe it is backed by an extensive test suite. I trust both it and gzip very strongly.
Add lzop to your testing, it has a slightly lower compression ratio, but much higher compression speed.
I will for part 2, but for this part 1 you can see lzop included in the Practical Compressor Test I linked to.
“7za already has a parallel LZMA implementation”
Really? If so, it is undocumented, at least for Unix (no mention of it in the manpage, which seems identical to the 7zr one, and the html manual is Windows dependent garbage).
See /usr/share/doc/p7zip/DOCS/MANUAL/switches/method.htm. It’s -mmt=on.
The manpage suggests you check out the full manual in /usr/share/doc, which goes over the various options. In particular, -mt will enable multithreading, but only for specific formats.
This is the exact reason why I’ve always been using gzip to compress data for backups. The explanation looks much better with nice charts, of course.
I would say that the 50GB of backups per day scenario is an outlier, and for most other scenarios the absolute cost of the CPU time is quite small. I typically run short of hard drive space far more often than my computer can’t keep up with the compression I want it to do.
Perhaps it is for a home user. I can assure you it’s not for a business, and probably less and less for home users too, considering that cheap DV cameras record at something like 30Mb/s.
A full backup at work easily exceeds 1TB, and our nightly incrementals are probably never less than 100GB.
Remember that the makeup of your backups can make a huge difference here. Video is a relatively specialized type of data that generally does best with specialized compression types (such as provided by the various video codecs).
At my company, we also generate very large backups. However, our backups are largely database dumps, which equates to highly compressible text-oriented data. This is an area that bzip2 excels at, and we’ve made use of it at times with good results.
One caveat to consider is the amount of RAM used in performing this backup. LZMA likes big dictionaries, which can consume a lot of RAM during compression.
1. Gzip solved the compression problem with all practicality. It will only be superceded when another algorithm reaches the same installed base
2. However, the case-by-case basis of compression is very interesting. For example things like squashfs: Compress an ubuntu live cd as well as possible, so that as much of ubuntu as possible can be available on a 700M disk.
There’s one point which might make me a minority, but I have a pair of resource constrained PCs (apart from the wireless access points being even more so). I have no problem running gzip on them, so I agree gzip still has its place :)
I had actually given up running lzma on one of them, a 400MHz K6 with 64M(+256M swap) simply could not finish an ~50MB file with lzma over the weekend. Your article made me realise I should check the man page, and indeed, the default is lzma -7, which would use 83MB memory, so it explains why it simply didn’t work for me. OTOH, bzip2 -9v just compresses it fine, albeit slowly — although about three times slower than gzip -9. So, siding with jldugger, lzma is on the borderline of staying viable on these machines.
I know 64MB may seem very ancient, but there are still new embedded (phone, router, access point) platforms coming out with this much or less memory. I’m starting to be scared to see what runs on Amiga with 6MB of memory :)
It would also be nice to know how fast they decompress.
I didn’t test that due to time constraints, but the Gimp article I linked to did.
7zip can only use two threads for lzma compression currently. However it has an implementation of bzip2 which can use more threads.
Actually, the day before yesterday I was wondering with some people over irc which implementation would be faster/compress more. If you have time maybe you could benchmark that too. :)
It seems to me that there are several issues one must simultaneously consider when choosing a compression algorithm.
1. How fast must the compression take?
2. How small must the compression be?
3. How much computer resources does compression take?
4. How fast must the DEcompression take?
5. How much computer resources does DEcompression take?
Looking at the three algorithms I am familiar with (gzip, bzip2, and lzma):
1. gzip is the clear winner in speed and computer resources required to compress/decompress, but is the clear looser in size
2. lzma is the clear winner in size, the clear looser in computer resources for compress/decompress, the clear looser in time to compress, and the second best in time to decompress
3. bzip2 is not the clear winner in any category
Based on these, I would say that bzip2 is completely deprecated except for the following two cases:
1. where size is important but resources for compression are extremely limited (even then I still might go with gzip unless size were really important), and
2. where size is paramount and I cannot be certain the decompression client has access to lzma tools
Hi,
according to http://de.wikipedia.org/wiki/Lempel-Ziv-Markow-Algorithmus#Portabilit.C3.A4t_der_Referenzimplementation (sorry in German), p7zip is better than LZMA Utils. Can you also test p7zip?
Is there a possibilty to use lzma like gzip or bzip2 as parameter in tar (like tar zcf or tar jcf). I do not want to create a temorary tar file and then run the compression tool over it…
I actually did; see the 7za output on the charts. There are a huge number of parameters to be tweaked there, and I chose one somewhat arbitrarily.
I am a bit puzzled why it would do better than lzma, since they are supposed to be the same algorithm, and even appear to be using the same SDK.
However, the p7zip tools may or may not be appropriate for general use because you might not be able to pipe into them.
You can use any pipable compressor with tar:
tar -cf – somedir | lzma > file.tar.lzma
same works with gzip or bzip2, and that’s what we did before tar got -j. That does not create a temporary file anywhere.
(p)7zip has some compression filters so it should provide better compression than pure lzma. However it doesn’t have many. IIRC it may currently only have BCJ/BCJ (they target binaries and may depend on/work better with windows’s PE format than linux’s ELF).
Filters should only appear with 7zip 5, the reason is the author wants to get a stable 7zip before messing with filters. You could find some on the 7zip’s sourceforge forums.
The (german) article at wikipedia doesn’t actually say that p7zip is better than lzma-utils. It just says that lzma-utils usually uses an older version of the lzma algorithm(s) than p7zip.
I’m a huge fan of gzip, but I wouldn’t quite go so far as to throw out bzip2. Especially when you include pbzip2 in the mix, I think it definitely still has a place.
It’s all a matter of using the appropriate compression depending on your requirements. Some people have strict space requirements, some have strict time requirements, and some have strict resource constraint requirements. Some have a combination, or other requirements beyond these.
The trick is to know what options are available, and make an informed decision.
Also note: I used to be much less of a fan of bzip2 than I am now. The rapid rise in CPU cores coupled with pbzip2 has changed my mind, though. On a lot of modern multi-core boxes, pbzip2 will outperform gzip in both compression time and compression level. Yes, it will use more CPU resources, but that is very often a worthwhile tradeoff. When and if implementations of the other compression algorithms make such effective use of parallelism, my opinion of bzip2 may drop again (although, my understanding is that bzip2’s design lends itself better to parallelism than most other compression algorithms).
Maybe you didnt know it but lzma utils are deprecated and all further development was put into xz-utils. Can you maybe add a test with it? The numbers are probably changed with xz now: http://tukaani.org/xz/ (yes, the basic algorithm is still lzma, but finer tuned and better on-disk format)
That’s not true. The latest release was on Feb 3, just a few weeks ago. See http://www.7-zip.org/sdk.html
I may look into xz though, as well as a newer LZMA.
You know that lzma sdk is something different than lzma-utils. The first one is the implementation taken from 7z which stores the lzma stream without any further headers… which is somewhat suboptimal and isn’t like the stuff you expect from a gzip-like utility.
lzma-utils (or better to say xz-utils now) has a better on-disk format with really headers and checksums and works like gzip or bzip2. Additional you can use the filters from 7zip. If you want to use lzma in a tool you should definitely try libxz instead of the lzma sdk.
For backup purposes, a ultra-high compression ratio isn’t really that relevant. However, data safety is.
Here neither gzip or bzip2, lzma, 7zip formats do you any good. I’m actually thinking about using good old outdated zip or even rar, which actually COULD recover from corrupt sectors. (bzip2recover is a complete joke)
– Yes, that’s still a possibility – even on modern external HDDs or DVD-RAM and SD-Cards , that I use for redundant backups.
Did you use threads?
Only with pbzip2.
I also suggest checking out lzop. It can be fast than catting directly to disk, depending on your transfer rates and CPU.
Your test suffers from the same problem as the Gimp tests, though perhaps to a lesser degree: it’s not really a representative test. First, because nobody backs up /usr — just save the list of packages, so you can re-install later. But also, in your use case of 50GB of photos a day, would anybody tar-and-compress these? Photos don’t tend to (losslessly) compress very well at all. In that case cat might be smaller than any of these algorithms!
Graphing the data is cool, but (as all my science teachers told me) they should really show error bars, or a distribution cloud, or something. For example, multiple points for each algorithm: “10GB text files”, “10GB raw photos”, “10GB compressed audio”, etc. You’re trying to show how it applies to a distribution of different file types, by running it on a distribution of different file types, but there’s nothing to suggest that one distribution of inputs is the same as the other. Is your /usr full of ELF binaries and already-compressed manpages and bitmaps, like mine is? That’s not representative of my ~ at all.
Finally, at least 3 different backup geeks have told me not to compress (or worse, encrypt) backups. When your primary data is gone, the number one thing you want above all else is to make it really really easy to get a copy of your data back. A single .tar.gz does not make it easy to get at one file you need, and if even one bit is bad, you can kiss the whole thing goodbye.
Nice analysis of compression, though. Good to know the limitations of the tools available.
Of course a distribution cloud would be helpful. I don’t have the time to devote weeks to generating and testing on massive data sets.
I back up /usr, and a lot of other people do too, because it is faster to restore from backup than to try to figure out how to make $PACKAGE_TOOL restore just /usr without touching /var or /etc, not to mention in the precise versions you had, some of which may have been locally-built.
As to use for backup safety, there is a grain of truth there, but it’s overstated. It is true that, with gzip, a bad bit at the beginning of a file could make you lose the entire rest of it. That’s not true with bzip2; your losses there are 900K at most. And this is precisely why many modern backup programs that support software compression reset it on a fixed blocksize, or at worst, on each file. Think of it more like zip than tar.gz, where the files are compressed before being put into the archive container.
I’ll post a part 2 tonight that looks at performance of these tools when compressing individual files for writing back out to disk, as may happen for instance with rdup or other hardlink-based schemes.
This is kind of anecdotal, but I made a Linux upgrade DVD for my company that boots into a custom Ubuntu LiveCD and basically untars the root directory onto the appropriate partition (with config mods afterwards). I originally used bzip2 but made a mistake and used gzip for the second revision, and I noticed that the gzipped version installs substantially faster (20-33%). Not sure why, but it might have something to do with the CPU usage.
IMHO “backup” and “compression” shlould never be used in the same sentence. There is far to much that can go wrong (bad sector, filesystem corruption, etc.) with a backup medium to add another layer of uncertainty.
And if you tell me you can not afford to back up uncompressed then maybe your data is not all that valuable to begin with.
for very large, repetitive xml files (wikipedia dumps), 7z gets stupendously better compression (like 10x better) than bzip2 or gzip-anything.
It also takes 10 times longer (nb: before brion even wrote a parallelized bzip2) and crashes more often.
Another thing not mentioned is decompression time, are archives solid, will they play nice with rsync, and who knows how many other different things that may be important–but I guess that isn’t important as long as I can make pretty graphs with a single data point with whatever factors I decide are the only ones that matter!
That’s an oversimplification, and an extreme one at that. I’ve shown that lzma -1 is faster than bzip2 -9. I’m sure that 7za, perhaps even with default options, can be made to be slower than bzip2 — but it can be made to be faster, too.
I have no illusion of grandeur here. Of course there are always more questions. One thing I care about is how well various archive formats store all the data about POSIX filesystems — hardlinks, symlinks, and sparse files. Neither zip nor 7-zip do, which is a big issue for me. tar, of course, can do this.
If you want to whip up data on those other things, by all means post a link to it here. I’d be interested.
A link to a previous compression-related blog with a graph, using SQL text dumps as the input data: http://blog.nickj.org/2007/07/06/comparing-compression-options-for-text-input/
7zip was quite good, and RAR too.
The main factor for me is that everyone has gzip and bzip2 installed (and most people have zip). Far fewer people have 7-Zip.
There are tools which beat bzip2 simultaneously on both compression effectiveness and compression/decompression speed. However, there is no tool which beats it simultaneously on both compression effectiveness and market penetration. As such, it still hits a “sweet spot”.
You have parallel bzip2, how about parallel gzip (pigz)?
http://www.zlib.net/pigz/
It would be interesting to know the results of
zip and pigz (paraller gzip) too as well as decompression times.
And test with http://rzip.samba.org/ would also be interesting
pbzip2 wins the speed test for me since 8 cores is the minimal install these days, but if you do the per file compression mentioned in part 2 the pbzip2 edge might not be so big. But pbzip2 is ridiculously fast on 8 core systems, I get 350MB/s which is faster than I can write to disks.
Though I have a friend who told me that pbzip2 crashed on him, so it’s not safe yet.