Yesterday, I posted part 1 of how to think about compression. If you haven’t read it already, take a look now, so this post makes sense.
Introduction
In the part 1 test, I compressed a 6GB tar file with various tools. This is a good test if you are writing an entire tar file to disk, or if you are writing to tape.
For part 2, I will be compressing each individual file contained in that tarball individually. This is a good test if you back up to hard disk and want quick access to your files. Quite a few tools take this approach — rdiff-backup, rdup, and backuppc are among them.
We can expect performance to be worse both in terms of size and speed for this test. The compressor tool will be executed once per file, instead of once for the entire group of files. This will magnify any startup costs in the tool. It will also reduce compression ratios, because the tools won’t have as large a data set to draw on to look for redundancy.
To add to that, we have the block size of the filesystem — 4K on most Linux systems. Any file’s actual disk consumption is always rounded up to the next multiple of 4K. So a 5-byte file takes up the same amount of space as a 3000-byte file. (This behavior is not unique to Linux.) If a compressor can’t shrink enough space out of a file to cross at least one 4K barrier, it effectively doesn’t save any disk space. On the other hand, in certain situations, saving one byte of data could free 4K of disk space.
So, for the results below, I use du to calculate disk usage, which reflects the actual amount of space consumed by files on disk.
The Tools
Based on comments in part 1, I added tests for lzop and xz to this iteration. I attempted to test pbzip2, but it would have taken 3 days to complete, so it is not included here — more on that issue below.
The Numbers
Let’s start with the table, using the same metrics as with part 1:
| Tool | MB saved | Space vs. gzip | Time vs. gzip | Cost |
|---|---|---|---|---|
| gzip | 3081 | 100.00% | 100.00% | 0.41 |
| gzip -1 | 2908 | 104.84% | 82.34% | 0.36 |
| gzip -9 | 3091 | 99.72% | 141.60% | 0.58 |
| bzip2 | 3173 | 97.44% | 201.87% | 0.81 |
| bzip2 -1 | 3126 | 98.75% | 182.22% | 0.74 |
| lzma -1 | 3280 | 94.44% | 163.31% | 0.63 |
| lzma -2 | 3320 | 93.33% | 217.94% | 0.83 |
| xz -1 | 3270 | 94.73% | 176.52% | 0.68 |
| xz -2 | 3309 | 93.63% | 200.05% | 0.76 |
| lzop -1 | 2508 | 116.01% | 77.49% | 0.39 |
| lzop -2 | 2498 | 116.30% | 76.59% | 0.39 |
As before, in the “MB saved” column, higher numbers are better; in all other columns, lower numbers are better. I’m using clock seconds here on a dual-core machine. The cost column is clock seconds per MB saved.
Let’s draw some initial conclusions:
- lzma -1 continues to be both faster and smaller than bzip2. lzma -2 is still smaller than bzip2, but unlike the test in part 1, is now a bit slower.
- As you’ll see below, lzop ran as fast as cat. Strangely, lzop -3 produced larger output than lzop -1.
- gzip -9 is probably not worth it — it saved less than 1% more space and took 42% longer.
- xz -1 is not as good as lzma -1 in either way, though xz -2 is faster than lzma -2, at the cost of some storage space.
- Among the tools also considered for part 1, the difference in space and time were both smaller. Across all tools, the difference in time is still far more significant than the difference in space.
The Pretty Charts
Now, let’s look at an illustration of this. As before, the sweet spot is the lower left, and the worst spot is the upper right. First, let’s look at the compression tools themselves:
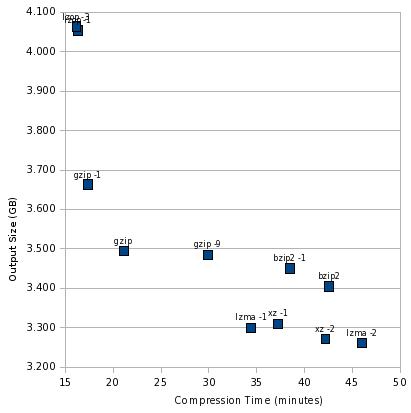
At the extremely fast, but not as good compression, end is lzop. gzip is still the balanced performer, bzip2 still looks really bad, and lzma -1 is still the best high-compression performer.
Now, let’s throw cat into the mix:
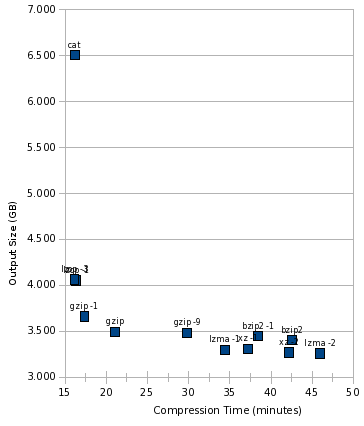
Here’s something notable, that this graph makes crystal clear: lzop was just as fast as cat. In other words, it is likely that lzop was faster than the disk, and using lzop compression would be essentially free in terms of time consumed.
And finally, look at the cost:
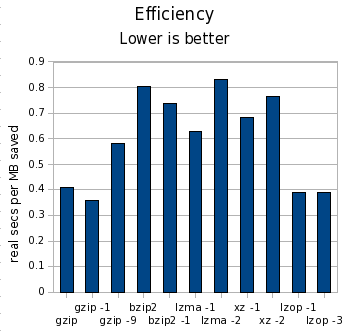
What happened to pbzip2?
I tried the parallel bzip2 implementation just like last time, but it ran extremely slow. Interestingly, pbzip2 < notes.txt > notes.txt.bz2 took 1.002 wall seconds, but pbzip2 notes.txt finished almost instantaneously. This 1-second startup time for pbzip2 was a killer, and the test would have taken more than 3 days to complete. I killed it early and omitted it from my results. Hopefully this bug can be fixed. I didn’t expect pbzip2 to help much in this test, and perhaps even to see a slight degradation, but not like THAT.
Conclusions
As before, the difference in time was far more significant than the difference in space. By compressing files individually, we lost about 400MB (about 7%) space compared to making a tar file and then combining that. My test set contained 270,101 files.
gzip continues to be a strong all-purpose contender, posting fast compression time and respectable compression ratios. lzop is a very interesting tool, running as fast as cat and yet turning in reasonable compression — though 25% worse than gzip on its default settings. gzip -1 was almost as fast, though, and compressed better. If gzip weren’t fast enough with -6, I’d be likely to try gzip -1 before using lzop, since the gzip format is far more widely supported, and that’s important to me for backups.
These results still look troubling for bzip2. lzma -1 continued to turn in far better times and compression ratios that bzip2. Even bzip2 -1 couldn’t match the speed of lzma -1, and compressed barely better than gzip. I think bzip2 would be hard-pressed to find a comfortable niche anywhere by now.
As before, you can download my spreadsheet with all the numbers behind these charts and the table.
> For part 2, I will be compressing each individual file
> contained in that tarball individually. This is a good
> test if you back up to hard disk and want quick
> access to your files.
For this cases, I like squashfs!
Great analysis.
I’d like to see the numbers for decompression as well. There are a lot of cases where I’d be willing to pay a lot of computing time during compression as long as decompression isn’t too bad. If I’m putting something up for public download, for example, it’s going to be compressed just once, but decompressed by every single person who downloads it.
Great. The last time i made a gzip/bzip2 decission for my backups must be 2 years ago.
My reults are, the data is compressed with gzip because bzip2 was too slow fot the network and the tape. But i use bzip2 for my backup database to easily search for files in the backups because bzip2 saves me a lot of disk space compared to gzip.
I’ve been wondering how to describe my results using debootstrap. I got into it by wanting to use the –save-tarball as well as (unrelated to this post, directly anyway, learn how to –second-stage scripting from Neil Williams emdebian stuff)
I debootstraped all etch variants ( I wanted to get a copy before I couldn’t easily anymore)
When the minbase vairant of etch is tarballed it is 31386007 bytes – I thought to myself Nice…
Also wanting to know what the others looked like and in case I needed them too.
buildd is 52514446 and fakechroot is 45102635
I’ve been intrigued by the notion of this thing called pristine tar since I first heard Joey Hess blog of it around the time he was moving from svn to git iirc..
“minbase seems to me at this point” to be a pristine debain install – although I have already removed all important priority packages as well using cat and diff to get the list from dpkg/info file.
After unpacking the tarball I got an urge to test tar on what I thought would be a decent test target.
So I
first made a copy of the minbase system
cp -a /mnt/md6 /srv/pristine.minbase
du -b /srv/pristine.minbase 92913288
than I made archives using tar, and tar switches for gzip, bzip2 and lzma
tar -xf pristine.tar /mnt/md6/*
tar -xzf pristine.tar.gz /mnt/md6/*
tar -xjf pristine.tar.bz2 /mnt/md6/*
tar -xf –lzma pristine.tar.lzma /mnt/md6/*
iirc
ls -l /srv
shows interestingly
drwxr-xr-x 20 root root 4096 2009-02-03 00:30 pristine.minbase
-rw-r–r– 1 root root 96634880 2009-02-03 11:56 pristine.tar
-rw-r–r– 1 root root 32455598 2009-02-03 11:58 pristine.tar.bz2
-rw-r–r– 1 root root 37310068 2009-02-03 11:57 pristine.tar.gz
-rw-r–r– 1 root root 22177523 2009-02-03 12:01 pristine.tar.lzma
Have I forgotten anything?
Did you use threads?
Graphs that don’t start at zero are misleading and thus worse than useless.
The scale is plainly visible. Sometimes the difference between numbers is such that in a size to be able to fit in a blog post, starting it at zero would be useless itself.
You might be interested to google for pigz (parallel version of gzip). Personally, I use lzop (since it is free) or pigz as a good trade off. LZMA is good where time is not a factor (decompression speed is reasonable).
Did you have a chance to look at FreeArc.org?
I was impressed the time was comparable to Bzip2, but compressed 20-30% better.