… and the case against bzip2
Compression is with us all the time. I want to talk about general-purpose lossless compression here.
There is a lot of agonizing over compression ratios: the size of output for various sizes of input. For some situations, this is of course the single most important factor. For instance, if you’re Linus Torvalds putting your code out there for millions of people to download, the benefit of saving even a few percent of file size is well worth the cost of perhaps 50% worse compression performance. He compresses a source tarball once a month maybe, and we are all downloading it thousands of times a day.
On the other hand, when you’re doing backups, the calculation is different. Your storage media costs money, but so does your CPU. If you have a large photo collection or edit digital video, you may create 50GB of new data in a day. If you use a compression algorithm that’s too slow, your backup for one day may not complete before your backup for the next day starts. This is even more significant a problem when you consider enterprises backing up terabytes of data each day.
So I want to think of compression both in terms of resulting size and performance. Onward…
Starting Point
I started by looking at the practical compression test, which has some very useful charts. He has charted savings vs. runtime for a number of different compressors, and with the range of different settings for each.
If you look at his first chart, you’ll notice several interesting things:
- gzip performance flattens at about -5 or -6, right where the manpage tells us it will, and in line with its defaults.
- 7za -2 (the LZMA algorithm used in 7-Zip and p7zip) is both faster and smaller than any possible bzip2 combination. 7za -3 gets much slower.
- bzip2’s performance is more tightly clustered than the others, both in terms of speed and space. bzip2 -3 is about the same speed as -1, but gains some space.
All this was very interesting, but had one limitation: it applied only to the gimp source tree, which is something of a best-case scenario for compression tools.
A 6GB Test
I wanted to try something a bit more interesting. I made an uncompressed tar file of /usr on my workstation, which comes to 6GB of data. My /usr contains highly compressible data such as header files and source code, ELF binaries and libraries, already-compressed documentation files, small icons, and the like. It is a large, real-world mix of data.
In fact, every compression comparison I saw was using data sets less than 1GB in size — hardly representative of backup workloads.
Let’s start with the numbers:
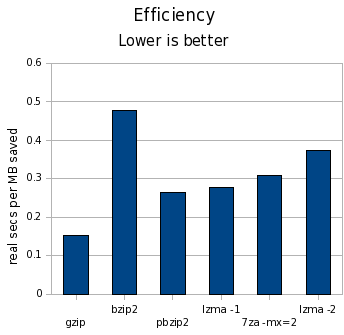
| Tool | MB saved | Space vs. gzip | Time vs. gzip | Cost | gzip | 3398 | 100.00% | 100.00% | 0.15 |
|---|---|---|---|---|
| bzip2 | 3590 | 92.91% | 333.05% | 0.48 |
| pbzip2 | 3587 | 92.99% | 183.77% | 0.26 |
| lzma -1 | 3641 | 91.01% | 195.58% | 0.28 |
| lzma -2 | 3783 | 85.76% | 273.83% | 0.37 |
In the “MB saved” column, higher numbers are better; in all other columns, lower numbers are better. I’m using clock seconds here on a dual-core machine. The cost column is clock seconds per MB saved.
What does this tell us?
- bzip2 can do roughly 7% better than gzip, at a cost of a compression time more than 3 times as long.
- lzma -1 compresses better than bzip2 -9 in less than twice the time of gzip. That is, it is significantly faster and marginally smaller than bzip2.
- lzma -2 is significantly smaller and still somewhat faster than bzip2.
- pbzip2 achieves better wall clock performance, though not better CPU time performance, than bzip2 — though even then, it is only marginally better than lzma -1 on a dual-core machine.
Some Pretty Charts
First, let’s see how the time vs. size numbers look:
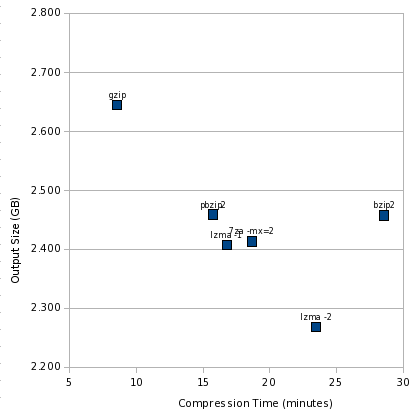
Like the other charts, the best area is the lower left, and worst is upper right. It’s clear we have two outliers: gzip and bzip2. And a cluster of pretty similar performers.
This view somewhat magnifies the differences, though. Let’s add cat to the mix:
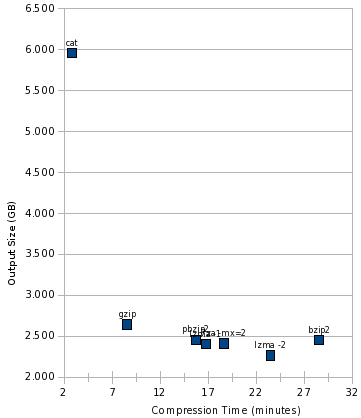
And finally, look at the cost:
Conclusions
First off, the difference in time is far larger than the difference in space. We’re talking a difference of 15% at the most in terms of space, but orders of magnitude for time.
I think this pretty definitively is a death knell for bzip2. lzma -1 can achieve better compression in significantly less time, and lzma -2 can achieve significantly better compression in a little less time.
pbzip2 can help even that out in terms of clock time on multicore machines, but 7za already has a parallel LZMA implementation, and it seems only a matter of time before /usr/bin/lzma gets it too. Also, if I were to chart CPU time, the numbers would be even less kind to pbzip2 than to bzip2.
bzip2 does have some interesting properties, such as resetting everything every 900K, which could provide marginally better safety than any other compressor here — though I don’t know if lzma provides similar properties, or could.
I think a strong argument remains that gzip is most suitable for backups in the general case. lzma -1 makes a good contender when space is at more of a premium. bzip2 doesn’t seem to make a good contender at all now that we have lzma.
I have also made my spreadsheet (OpenOffice format) containing the raw numbers and charts available for those interested.
Update
Part 2 of this story is now available, which considers more compression tools, and looks at performance compressing files individually rather than the large tar file.